概念
Transformer模型(直译为“变换器”)是一种采用自注意力机制的深度学习模型,解决sequence-to-sequence问题。这一机制可以按输入数据各部分重要性的不同而分配不同的权重。该模型主要用于自然语言处理(NLP)与计算机视觉(CV)领域。
与循环神经网络(RNN)一样,Transformer模型旨在处理自然语言等顺序输入数据,可应用于翻译、文本摘要等任务。而与RNN不同的是,Transformer模型能够一次性处理所有输入数据。注意力机制可以为输入序列中的任意位置提供上下文。如果输入数据是自然语言,则Transformer不必像RNN一样一次只处理一个单词,这种架构允许更多的并行计算,并以此减少训练时间。
Transformer模型于2017年由谷歌大脑的一个团队推出,现已逐步取代LSTM等RNN模型成为了NLP问题的首选模型,并行化优势允许其在更大的数据集上进行训练。这也促成了BERT、GPT等预训练模型的发展。这些系统使用了维基百科、Common Crawl等大型语料库进行训练,并可以针对特定任务进行微调。
背景
顺序处理
门控RNN模型按顺序处理每一个标记(token)并维护一个状态向量,其中包含所有已输入数据的表示。如要处理第N个标记,模型将表示句中到第N-1个标记为止的状态向量与最新的第N个标记的信息结合在一起创建一个新的状态向量,以此表示句中到第N个标记为止的状态。从理论上讲,如果状态向量不断继续编码每个标记的上下文信息,则来自一个标记的信息可以在序列中不断传播下去。但在实践中,这一机制是有缺陷的:梯度消失问题使得长句末尾的模型状态会缺少前面标记的精确信息。此外,每个标记的计算都依赖于先前标记的计算结果,这也使得其很难在现代深度学习硬件上进行并行处理,这导致了RNN模型训练效率低下。
注意力机制
注意力机制解决了上述这些问题。这一机制让模型得以提取序列中任意先前点的状态信息。注意力层能够访问所有先前的状态并根据学习到的相关性度量对其进行加权,从而提供相距很远的标记的相关信息。
Transformer模型采用了没有RNN模型的注意力机制,它能够同时处理所有标记并计算它们之间的注意力权重。由于注意力机制仅使用来自之前层中其他标记的信息,因此可以并行计算所有标记以提高训练速度。
原理架构
与早期的seq2seq模型一样,原始的Transformer模型使用编码器-解码器(encoder–decoder)架构。编码器由逐层迭代处理输入的编码层组成,而解码器则由对编码器的输出执行相同操作的解码层组成。下图左边为encoder,右边为decoder:

每个编码层的功能是确定输入数据的哪些部分彼此相关。它将其编码作为输入再传递给下一个编码层。每个解码层的功能则相反,读取被编码的信息并使用集成好的上下文信息来生成输出序列。为了实现这一点,每个编码层和解码层都使用了注意力机制。
对于每个输入,注意力会权衡每个其他输入的相关性,并从中提取信息以产生输出。每个解码层都包含一个额外的注意力机制,它会在从编码层提取信息之前先从之前解码器的输出中提取信息。
编码层和解码层都有一个前馈神经网络用于对输出进行额外处理,并包含残差连接和层归一化步骤
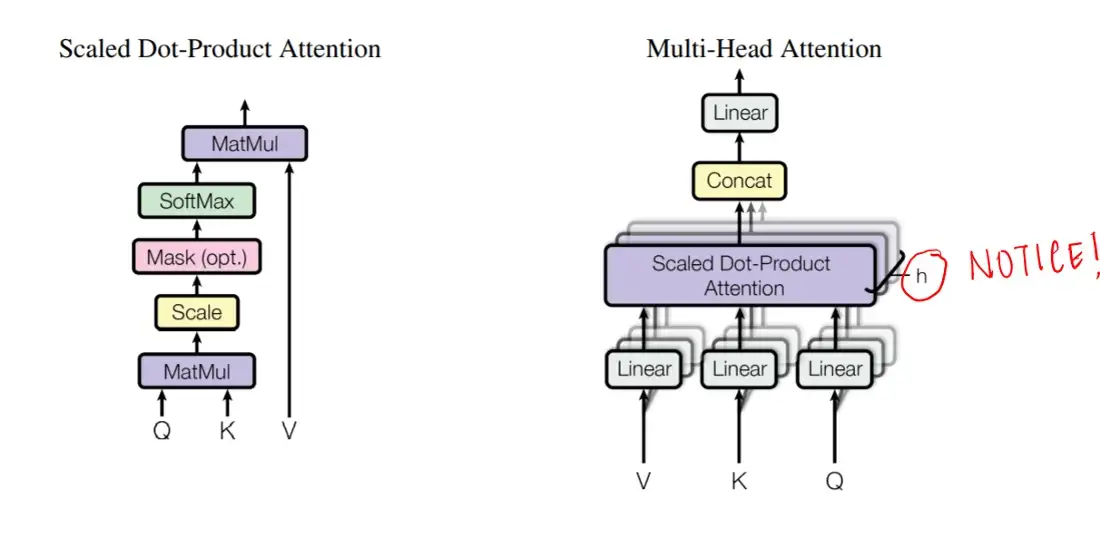
Transformer模型的基本构建单元是缩放点积注意力(scaled dot-product attention)单元。当一个句子被传递到一个Transformer模型中时,可以同时计算所有标记互相之间的注意力权重。注意力单元为上下文中的每个标记生成嵌入,其中包含有关标记本身的信息以及由注意力权重加权得到的其他相关标记的信息。


对所有标记的注意力计算可以表示为使用softmax函数的一个大型矩阵计算,由于可以对矩阵运算速度进行优化,这十分利于训练速度的提升。矩阵Q、K和V可分别定义为第i行是向量\(q_i、k_i、v_i\)的矩阵

替代架构
训练基于Transformer模型的架构可能很代价较高,尤其是对于长输入而言。替代架构包括Reformer模型、ETC/BigBird模型等,前者可以将计算复杂度从\(O(N^2)\)减少为O(NlnN) ,后者则可以减少到O(N),其中
训练
Transformer模型通常会进行自监督学习,包括无监督预训练和监督微调。由于监督微调时使用的带标签训练数据一般比较有限,预训练通常会在比微调时所用的更大的数据集上完成。