概念
NMF为非负矩阵分解,将一个矩阵V分解成两个更小的矩阵W和H,并且这三个矩阵都没有负数元素。
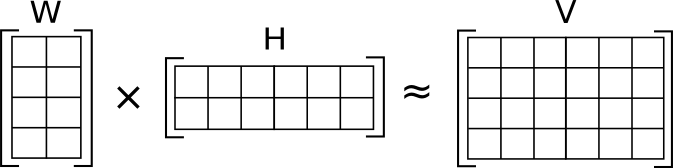
比如,V为m*n矩阵,W是m*p矩阵,H是p*n矩阵,p往往远小于m和n
- 假如V为10000*500的矩阵,每行代表words,每列代表documents
- 假设我们需要一个算法找到10个特征,生成一个10000*10的特征矩阵W,和一个10*500的系数矩阵H
- 如果因式分解有效,W与H的乘积是输入矩阵V的有效接近
- WH是特征矩阵W10个列向量的线性组合
最后一点是NMF的基础,因为我们可以认为样例中每篇document都是由我们一个规模较小的特征集合构建而来。
聚类属性
WH对V的接近是通过最小化误差函数来实现的,如果我们进一步对H施加正交约束,即\(HH^T\)=I,那么这种最小化就等价于K-means聚类的最小化。H给出了簇的所属关系,如果对任意i≠k,\(H_{kj}>H_{ij}\),则表明数据\(v_j\)属于第k个簇,而W的第k列给出了第k个簇的簇心
由于可使用的衡量WH与V之间差异的代价函数不同,有多种不同的分解办法。
步骤
非负矩阵分解中,代码采用的是原始论文中提及的基于乘法更新发展的迭代更新算法,其将矩阵分解算法转化为如下的优化问题,即最小化两个矩阵之间的欧几里得距离的优化问题:
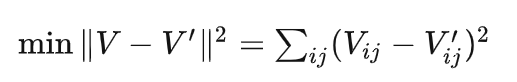
其中V为原始矩阵,V’为分解后的矩阵重构而成的矩阵,即V’=H*W
乘法更新规则:

算法流程

我们要分出8个主特征,即r=8。原始图像中的每两个数字构成一个子图,由64*64个像素组成,共有64个子图,每个子图被张成一个4096(64^2)的向量,因此V矩阵为4096*64维的矩阵。
1、随机初始化一个4096行8列的矩阵W和一个8行64列的矩阵H,设定误差阈值ϵ和迭代轮数iternum
2、按照上述的乘法更新规则更新(即(1)和(2)式)W和H矩阵,迭代进行第二步
3、输出W矩阵,W矩阵的每一列即为一个特征,即对应的一个数字。将每一列重新展开为一个64*64的矩阵,转置后绘制出来,可看到对应的8个数字,得到结果如下图(1000轮迭代,大约9秒完成)。可看出非负矩阵分解可以很好地将原图中的特征提取出来。

与PCA比较

PCA就是求一组标准正交基,第一个基的方向取原数据方差最大的方向,然后第二个基在与第一个基正交的所有方向里再取方差最大的,这样在跟前面的基都正交的方向上一直取到k个基。所以PCA的基没有直观的物理意义,而且W和H里面的元素都是可正可负的,这就意味着还原时是用W的基加加减减得到的。
NMF因为约束了非负,所以只准把基相加,不能相减,这就意味着基与基是通过拼接组合来还原原象的。NMF分解后的基矩阵H是每张人脸的一个特征部分,例如眼睛,鼻子,嘴巴等,然后权重矩阵对这些特征进行加权处理从而得到一张完整的人脸。