概念
GRU(Gated Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和梯度消失等问题而提出来的。GRU比LSTM多一个forget gate,少一个output gate,计算成本比LSTM更小,参数更少,更容易训练。
原理
GRU使用了update gate和reset gate两个向量,它们能够决定被传递给output的信息,并且训练之后可以保留很久之前的信息,移除与预测不相关的信息。
结构


update gate

\(h_{t-1}\)保存着之前t-1个时间单元的信息。
update gate帮助模型决定过去的信息有多少需要被传递

reset gate
决定遗忘多少过去的信息

与update gate相比,只有权重和门的用途不同

current memory content
使用reset gate来存储从过去得到的相关信息:
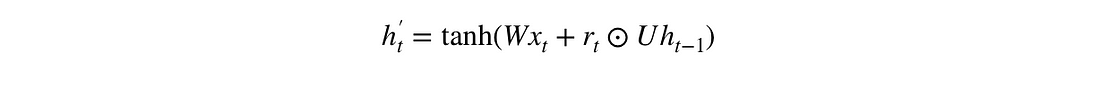
\(r_t\odot Uh_{t-1}\)Hadamard积决定从先前的时间步骤中移除哪些信息
例如现在有一个书评需要我们分析其中的态度,开头是“This is a fantasy book which illustrates…”过了很多段后结尾是“I didn’t quite enjoy the book because I think it captures too many details”,我们其实只需要评论的最后一部分来得到该读者的满意程度,这时候模型能学习给\(r_t\)分配一个接近0的向量,从而削弱之前段落的作用,聚焦于最后一句话。

final memory at current time step
最后一步是计算\(h_t\),是包含当前单元信息的向量,并把它传递到网络里,这需要update gate来决定从current memory content即\(h’_t\)、之前步骤即\(h_{t-1}\)里收集哪些信息。


Bidirectional GRU
双向GRU即BiGRU由两个GRU组成,一个将input进行正向处理,另一个再对其进行反向处理,是一种双向RNN结构。